

Web scraping, also known as web harvesting or web data extraction, is a process that involves the extraction of data from websites. This is typically done by writing an automated script or program that sends HTTP requests to the web pages of a specified website and then parses the HTML response to collect data.
Web scraping can be used to collect various types of data from the internet. For instance, businesses may use it to gather data on competitor prices, customer sentiment, or trending topics. Researchers might use it to analyze trends in blogs and forums or to gather data for machine learning projects. However, it’s important to note that it comes with ethical and legal considerations.
Not all websites allow this, and in some cases, scraping can be considered illegal or a violation of a website’s terms of service.
Here is a video by ParseHub about what is web scraping and what is it used for:
The complexity of the process can vary. Simple scraping tasks might only involve extracting static data from a single page, while more complex tasks might require interacting with forms, dealing with cookies, or navigating through a website’s multiple pages or layers.
Numerous tools and libraries in various programming languages aid in web scraping. For example, Python, a popular language for such tasks, has libraries like BeautifulSoup and Scrapy.
How Does Google Fight with Content Scraping
Google combats web scraping using several techniques, including bot detection through IP address blocking, user agent blocking, and CAPTCHAs. It limits the rate of requests a bot can make in a certain period and can block bots from accessing specific types of content. Legal actions can also be taken against bots violating its terms of service or scraping non-public data.
Meanwhile, webmasters can protect their websites using bot detection services, rate limiting requests, using CAPTCHAs, blocking known bot-associated IP addresses, employing a content delivery network (CDN), and monitoring website traffic to detect unusual patterns indicating scraping. The consequences of this action can be severe, including website overload, data theft, SEO penalties from Google, and potential legal actions.
So, it’s essential to consider these risks before engaging in web scraping.
Scraped content is content that has been copied from one website to another without permission. This can be done using a variety of methods, such as web or screen scraping. Copied content is often used to create low-quality websites that are designed to rank high in search engines.
Google has been cracking down on scraped content for a number of years. In 2016, Google released a new algorithm update called Panda, which was designed to penalize websites that contain low-quality content. This update was effective in reducing the amount of scraped content that appeared in search results.
The tweet from Matt Cutts is a further indication that Google is taking a tough stance on scraped content. This is good news for website owners who create high-quality content. It means that they will be less likely to be penalized by Google for the actions of others.
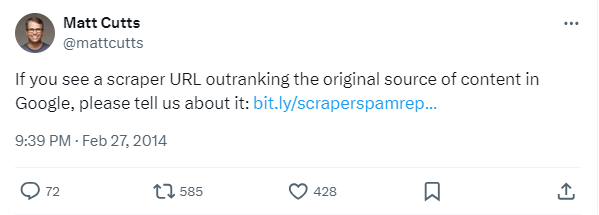
If you are concerned about your website’s SEO, it is important to avoid using scraped content. You should also make sure that your website is not copying content from other websites. If you are caught doing that, Google may penalize your website, which could hurt your search engine ranking.
How Safety Web Scraping Can be Used in SEO
Web scraping can be safely employed for SEO in various ways like competitor analysis, keyword research, link building metrics, content optimization, on-page SEO audits, SERP analysis, and tracking SEO progress. However, it should be conducted ethically and legally. Respect the website’s Terms of Service and robots.txt file, avoid overloading servers by limiting requests, only scrape public data, avoid scraping data requiring login, and seek permission when in doubt.
It’s important to note that scraping search engines like Google is against their terms of service. Instead, use official APIs or SEO tools that respect the guidelines provided by the platform. The essence is to carry out the process in a responsible and respectful manner.
Safe and ethical web scraping typically follows these principles:
- Respect the terms of service. Always refer to the website’s Terms of Service or robots.txt file. These might indicate whether web scraping is allowed and what parts of the website can be accessed by bots.
- Don’t overload servers. Making too many requests in a short time can overload a website’s server, which can disrupt its operation. To avoid this, you should implement rate limiting in your scraping program. This means limiting the number of requests you make per minute or hour.
- Scrape public data only. It’s important to only scrape data that is publicly available. Doing this with personal data could violate privacy laws.
- Avoid log-in requirement. If a website requires a login to access certain data, it’s typically a sign that this data is not intended for public consumption. Scraping such data can infringe on privacy rules and the website’s terms of service.
- Notify and seek permission. When in doubt, it’s a good idea to reach out to the website owner to ask for permission to scrape their site. This is the safest way to avoid potential legal issues.
Remember, scraping search engines directly, like Google, is against their terms of service. Use their official APIs or other SEO tools, which provide data in a manner that’s respectful of their terms. Similarly, for other websites, always follow the guidelines provided by the site’s owner and respect their rules and restrictions. It should be done ethically and responsibly.
Web Scraping Template for SEO
To create a web scraping template for SEO, first identify the data you need such as keywords, backlinks, or competitor content. Then, find the website(s) that contains this data and inspect the HTML elements to understand the site structure. Write a web scraper in a suitable language (like Python or JavaScript) to extract the data. Ensure that your tool works correctly by testing it, and then use it to gather your SEO data. Remember to choose a reputable web scraping tool, respect the terms of service of the websites you’re scraping, avoid collecting non-public data or overloading servers, and make good use of the collected data to improve your SEO strategy.
Before starting, you need to install Python and some required packages (requests, BeautifulSoup) if you haven’t done so already. In Python, you can install packages using pip:
pip install requests beautifulsoup4For this guide, let’s say we want to scrape Google search results to track how a particular website is ranking for specific keywords. Here’s a basic template:
import requests
from bs4 import BeautifulSoup
def scrape_google(keyword, site):
url = 'https://www.google.com/search?q=' + keyword
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.select('.g .yuRUbf a')
for i, link in enumerate(links, start=1):
if site in link['href']:
return i
return None
print(scrape_google('your keyword', 'yourwebsite.com'))
In this script:
- We import the necessary packages.
- We define a function scrape_google which takes a keyword and a site as input.
- We build the URL for the Google search of the keyword.
- We send a GET request to this URL with a header specifying the User-Agent. Note that many websites have restrictions on web scraping and this method might not always work or might be against their terms of service.
- We parse the response using BeautifulSoup.
- We select the links in the search results using CSS selectors.
- We loop over the links and return the rank of the first link that contains the specified site.
- If the site is not found in the search results, we return None.
You can run this function with different keywords to check how your website is ranking for each keyword.
This is a very basic example, and real-world web scraping tasks might be much more complex. Also, remember that it must be performed ethically and in accordance with all applicable laws and terms of service. Always respect the target website’s robots.txt file and be careful not to overload the server with too many requests.
Also, keep in mind that scraping search engines is against the terms of service of most of them, including Google. This is a simple illustrative example and not meant to encourage or endorse such activities. A more appropriate, approved, and reliable way to get search data from Google would be to use their official Google Search Console API or other similar SEO tools.
Empowering SEO Strategies: A Comprehensive Guide to the Link Extractor Tool
Collect data for every URL on your website
The link extractor tool serves to grab all links from a website or extract links on a specific webpage
Link Extractor tool is a revolutionary asset for SEO professionals and enthusiasts. It eases the complex process of web scraping, allowing users to extract crucial data, such as competitor prices and customer sentiment, from the myriad of web pages swiftly. Its user-friendly interface and advanced features make data extraction seamless, even from websites with multiple layers. It’s a boon for those looking to delve deep into SEO practices, providing insights and data that are pivotal for staying ahead in the digital realm.
Conclusion
Web scraping involves extracting data from websites for SEO purposes such as competitor analysis and keyword research. However, it must be done ethically and legally, respecting a website’s Terms of Service and public data accessibility.
Misused web scraping can lead to SEO penalties. Tools in languages like Python aid in responsible scraping, but direct scraping from search engines is generally prohibited.
What is the best language to learn for web scraping and interaction?
What is the difference between web scraping and web crawling?
What is Python web scraping?
Web scraping is used to extract what type of data?
What is web scraping for SEO?
Keyword research: Web scraping can be used to collect data on keywords that your competitors are using. This data can be used to identify new keywords that you can target in your own content.
Backlink analysis: It can be used to collect data on backlinks that are pointing to your competitors` websites. This data can be used to identify opportunities to build backlinks to your own website.
Content analysis: Web scraping can be used to collect data on the content that your competitors are publishing. This data can be used to identify trends, patterns, and insights that can be used to improve your own content.
Competitor analysis: Web scraping can be used to collect data on a variety of aspects of your competitors` businesses, including their products, services, pricing, and marketing strategies. This data can be used to gain a competitive advantage.
While it can be a useful tool for SEO, it is important to use it responsibly. It is important to follow the terms of service of the websites that you are scraping and to avoid revealing data that is not publicly available. Additionally, it is important to use it in a way that does not overload the websites that you are scraping.
 Response Code: Issues with 201 Status Codes")


