

What is a Web Crawler?
A web crawler, also known as a spider or bot, is an automated software program designed to navigate the vast expanse of the World Wide Web. Its primary function is to systematically browse and index content from websites, creating a comprehensive map that search engines like Google, Bing, and Yahoo use to deliver relevant search results.
Web crawlers start their journey from a list of web addresses or URLs. They visit these web pages, parse the content (text, images, videos, etc.), and then follow the links on these pages to other web documents. This interconnected trail of content and links allows crawlers to hop from one page to another, weaving through the intricate web of internet resources.
The Role of Web Crawlers in Search Engines
Search engines depend on web crawlers to update their indexes with fresh and updated content. This index acts like a giant library catalog, helping the search engine’s algorithms decide which pages are most relevant to a user’s search query. Without web crawlers, search engines would be outdated and inefficient, with search engine results leading to poor user experiences.
The Challenges Faced by Web Crawlers
While web crawling might sound straightforward, it comes with its set of challenges. Websites are diverse and complex, and not all web pages are built the same. Some pages have dynamic content, while others might have a structure that makes it difficult for web crawlers work to parse. Additionally, web crawlers must be respectful of a website’s robots.txt file, a set of rules set by webmasters indicating which parts of the site can or cannot be crawled.
In essence, a web crawler is a crucial component of the internet ecosystem, tirelessly working behind the scenes to ensure that search engines have the latest and most relevant data. They navigate the web’s complexities with precision, contributing significantly to our ability to find information quickly and efficiently.
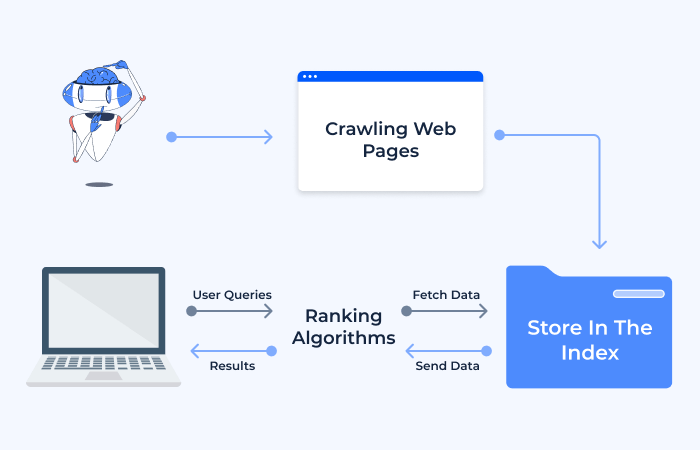
What is Web Crawling?
Web crawling is the automated process by which web crawlers (also known as spiders or bots) systematically browse the internet to collect data from websites. This crucial function serves as the backbone for search engines, enabling them to index the web and provide relevant search results to users. In this chapter, we’ll delve into the intricacies of web crawling, its purposes, and the mechanics behind it.
The Purpose of Web Crawling
The primary goal of web crawling is to gather information from websites to create an index, which search engines use to rank and display search results. Crawlers help in discovering new web pages, updating existing content in the search engine’s index, and identifying broken links. By doing so, they ensure that users have access to the most up-to-date and accurate information when performing a search.
How Web Crawling Works
Web crawlers start their journey with a list of URLs obtained from previous crawl processes and from sitemap files provided by websites. They visit these URLs, download the web page content, and parse it to extract links to other pages. Crawlers then add these new links to their list of URLs to visit, continuing the cycle.
During this process, crawlers must adhere to rules set by websites. These rules are often outlined in the robots.txt file of a website and may include directives on which parts of the site should not be crawled. Additionally, crawlers must be programmed to handle various content types and website structures, ensuring that they can navigate and index content accurately.
The Frequency and Challenges of Web Crawling
Web crawling is a continuous process, as the content on the web is constantly changing. The frequency at which a website is crawled depends on its size, the frequency of content updates, and its importance on the web. High-traffic and frequently updated websites may be crawled several times a day, while smaller, less frequently updated sites might be crawled less often.
Despite its automated nature, web crawling is not without challenges. Websites with complex navigation structures, heavy use of JavaScript, or strict robots.txt rules can be difficult for crawlers to navigate. Furthermore, the website crawlers themselves must be designed to be efficient and respectful of website resources, ensuring that they do not overwhelm a site’s server or violate any privacy policies.
Web crawling is a vital process that powers search engines, enabling them to provide timely and relevant search results. It requires a delicate balance of efficiency and respect for website rules, and it plays a critical role in organizing the vast amount of information available on the internet. Through web crawling, search engines are able to make sense of the web and connect users with the content they are seeking.
How Does a Web Crawler Work?
Web crawlers, while seeming mysterious to many, operate on a set of predefined rules and algorithms. They traverse the internet, indexing and updating the content of websites in a methodical manner. The operation of a web crawler involves a series of steps and interactions with website components, ensuring that all the pages and data collected is accurate, relevant, and up-to-date. In this chapter, we will delve deeper into the mechanisms of a web crawler and the essential components it interacts with during its journey.
Understanding the Robots.txt File
The robots.txt file is a crucial component in the world of web crawling. Located at the root of a website (e.g., https://example.com/robots.txt), it provides directives to web crawlers about which parts of the site should or shouldn’t be accessed.
- Purpose of the Robots.txt File: It helps website owners communicate with web crawlers. By specifying certain rules, site administrators can prevent crawlers from accessing sensitive areas of the site or guide them towards essential pages.
- Directives and User-agents: The robots.txt file contains directives like “Disallow” and “Allow”, guiding crawlers on where they can go. These directives can be specified for all crawlers (using a wildcard “*”) or tailored for specific crawlers (using their user-agent name).
- Crawl-Delay: Some robots.txt files also specify a “Crawl-Delay”, indicating how many seconds the crawler should wait between successive requests. This ensures that the web crawler doesn’t put undue strain on the website’s server.
While respecting the robots.txt file is a standard convention in the industry, it’s important to note that malicious bots can ignore these directives.
The Role of Robots Meta Tag
Beyond the robots.txt file, websites can also use the Robots Meta Tag to provide more granular instructions to web crawlers. These meta tags reside in the <head> section of individual web pages.
- Types of Directives: The Robots Meta Tag can include directives like “noindex” (indicating the page should not be indexed) and “nofollow” (telling the crawler not to follow the links on the page).
- Usage: A typical meta tag might look like this: <meta name=”robots” content=”noindex, nofollow”>, instructing crawlers not to index the page and not to follow its links.
The Robots Meta Tag offers a level of precision not available with the robots.txt file, allowing for specific instructions on a per-page basis.
Navigating Through Link Attributes
Web crawlers rely heavily on links to traverse the internet. However, not all links are treated the same, and websites can use link attributes to provide specific instructions to their own web crawlers about how to treat individual links.
- Rel=”nofollow”: This attribute tells the crawler not to follow the link to its destination. For example, <a href=”https://example.com” rel=”nofollow”>Link</a> indicates that the linked page shouldn’t be followed or considered for ranking.
- Rel=”sponsored”: Introduced to identify sponsored or paid links, this attribute ensures transparency in advertising and affiliate marketing practices.
- Rel=”ugc”: Standing for “User Generated Content”, this attribute is used for links within user-generated content, distinguishing them from editorial links.
These link attributes help web crawlers understand the context and purpose of links, ensuring that they provide the most relevant search results to users.
Types of Web Crawling
Web crawling is not a one-size-fits-all process. Different situations and objectives require different types of web crawls. Understanding these various types is crucial for anyone involved in SEO or web development. In this chapter, we’ll explore the broad categories of web crawls and delve into two specific types of crawls conducted by Google.
General Overview of Different Crawls
Web crawls can be categorized based on their purpose, scope, and the technologies they employ. Below is an overview of some common types:
| Full Site Crawl | This type involves crawling an entire website, covering every accessible page. It’s typically used for indexing purposes by search engines or to conduct SEO audits. |
| Focused Crawl | Unlike a full site crawl, focused crawls target specific sections of a site or specific types of content. This approach is more efficient when you have a particular goal in mind, such as updating a product catalogue or checking for broken links in a blog section. |
| Incremental Crawl | This crawl type focuses on content that has been added or updated since the last crawl. It’s essential for keeping search engine indexes fresh and up-to-date. |
| Deep Crawl | Deep crawls aim to reach as deep into a website’s structure as possible, often prioritizing pages that are several clicks away from the homepage. This is crucial for uncovering hidden content that might not be easily accessible. |
| Freshness Crawl | Search engines conduct freshness crawls to keep track of frequently updated content. News websites and blogs are common targets for these crawls. |
Two Specific Types of Google Crawls
Google, being the largest search engine, conducts billions of web crawls daily. Two specific types of crawls in Google’s arsenal are particularly noteworthy:
- Discovery Crawl: This type of crawl is all about finding new content. Google uses links from known pages to discover new pages and adds them to its index. It’s an ongoing process that ensures Google’s index is continuously updated with fresh content.
- Refresh Crawl: Once a page is in Google’s index, it needs to be regularly checked for updates. That’s where the refresh crawl comes in. Google revisits known pages to check for any changes or new content, ensuring that the information in the search results is current.
These crawls are integral to Google’s ability to provide timely and relevant search and search engine results page, showcasing the search engine’s commitment to a comprehensive and up-to-date index.
Building a Web Crawler or Using Web Crawling Tools: Which One to Choose?
Web crawling is a crucial component of data gathering and analysis on the internet. For businesses and individuals looking to harness the power of web crawling, a pivotal decision is whether to build an in-house web crawler or use third-party web crawling tools. In this chapter, we will explore the advantages and disadvantages of each option to help you make an informed decision.
In-House Web Crawlers
Building a web crawler tailored to your specific needs might seem like a daunting task, but it can be incredibly rewarding.
Advantages
- Customization: An in-house crawler can be customized to meet the exact requirements of your project. You have complete control over the crawling process, data extraction, and storage.
- Data Privacy: With your own crawler, sensitive data doesn’t have to leave your organization, ensuring complete privacy and security.
- Integration: An in-house solution can be seamlessly integrated with existing systems and workflows within your organization.
Disadvantages
- Resource Intensive: Building and maintaining a web crawler requires significant time, expertise, and financial resources.
- Scalability Issues: As your crawling needs grow, scaling an in-house solution can become challenging and resource-intensive.
- Maintenance: An in-house web crawler requires continuous maintenance and updates to adapt to changes in web technologies and structures.
Outsourced Web Crawlers
Leveraging third-party web crawling tools can be a more practical solution for many, especially those without the resources to develop an in-house solution.
Advantages
- Cost-Effective: Using an outsourced solution is often more cost-effective than developing an in-house crawler, especially for short-term or smaller-scale projects.
- Ease of Use: Many third-party tools are user-friendly and require less technical expertise to operate.
- Scalability: Outsourced web crawling services are designed to handle large-scale operations, providing scalability without the headache of managing infrastructure.
Disadvantages
- Limited Customization: While many tools offer a range of features, you may find yourself limited by the capabilities of the tool, especially for highly specific or complex crawling needs.
- Data Privacy Concerns: When using a third-party service, your data is handled by an external entity, potentially raising privacy and security concerns.
- Dependence on Vendors: Relying on an external service means depending on their reliability and stability. Any downtime or changes in their service can directly impact your operations.
Sponsored Tools and Services
Some third-party tools and services offer sponsored plans or features, providing additional resources or capabilities in exchange for certain conditions, such as displaying the provider’s branding or sharing data.
- Benefits: Sponsored tools can be a cost-effective way to access advanced features or increased capacity.
- Considerations: It’s important to carefully review the terms and conditions of sponsored plans to ensure they align with your organization’s policies and values.
Web Crawling Applications and Use Cases
Web crawling is a versatile technology with a myriad of applications across different sectors. It plays a pivotal role in data aggregation, analysis, and decision-making processes for businesses and individuals alike. In this chapter, we will explore various real-world examples and industry-specific applications of web crawling.
Real-World Examples of Web Crawling
Web crawlers are employed in various scenarios, serving multiple purposes:
| Search Engines | The most common use of web crawling is by search engines like Google, Bing, and Yahoo. They use crawlers to index the internet, helping to retrieve and display relevant search results to users. |
| Price Comparison | Websites use web crawlers to gather pricing information from various e-commerce platforms, providing users with the ability to compare prices for a specific product across different retailers. |
| Content Aggregation | News aggregators use crawlers to collect articles and posts from different news websites, presenting them in one centralized platform. |
| SEO Monitoring | Web crawling is crucial for SEO professionals to track website performance, backlinks, and keyword rankings. |
| Social Media Monitoring | Businesses use web crawlers to monitor mentions of their brand or products on social media platforms, enabling them to respond to customer feedback and manage their online reputation. |
| Academic Research | Researchers and academics use web crawlers to collect data from various sources on the internet, aiding in data analysis and research. |
How Different Industries Utilize Web Crawling
The application of web crawling extends to numerous industries, each leveraging the technology in unique ways:
- E-commerce: Retailers use web crawlers to monitor competitor prices, track product reviews, and gather product details from various sources.
- Real Estate: Web crawling is used to aggregate property listings from different websites, providing a comprehensive view of the real estate market.
- Finance: Financial analysts use crawlers to gather market data, news, and financial reports, aiding in investment decisions and market analysis.
- Healthcare: Web crawlers help in aggregating medical research, patient reviews, and information on drugs and treatments from various online sources.
- Travel and Tourism: Travel websites use web crawlers to gather information on hotel prices, flight fares, and user reviews, providing customers with a range of options and the ability to make informed decisions.
- Human Resources: Companies use web crawling to scan job portals and social media profiles for potential candidates, streamlining the recruitment process.
Web crawling is a powerful tool with a wide array of applications and use cases across different industries. From improving search engine accuracy to aiding in market research and monitoring online sentiment, the potential uses of web crawling are vast and varied. Understanding how to leverage this technology can provide significant advantages, regardless of the industry or field.
Web Crawling Challenges and Best Practices
Navigating the vast expanse of the internet via web crawling is a complex task that comes with its unique set of challenges. In this chapter, we will delve into some of the common obstacles encountered during web crawling and provide insights on best practices to ensure efficient and ethical crawling activities.
Challenges in Web Crawling
Web crawling, while powerful, is not without its difficulties. Below are some of the prevalent challenges:
Database Freshness
- Issue: Ensuring that the data collected is up-to-date and reflects the current state of the web.
- Impact: Outdated or stale data can lead to inaccurate analyses and misguided decisions.
- Mitigation: Implementing incremental crawls to frequently update the database and prioritize content that changes regularly.
Crawler Traps
- Issue: Websites may have infinite loops or complex URL structures that trap crawlers, causing them to crawl irrelevant or repetitive content indefinitely.
- Impact: Wasted resources, potential IP bans, and incomplete data collection.
- Mitigation: Setting up crawl depth limits, URL pattern recognition, and canonicalization to avoid traps.
Network Bandwidth
- Issue: Web crawling can consume significant network resources, affecting both the crawler’s and the target website’s performance.
- Impact: Slow website performance for users, and potential IP bans for the crawler.
- Mitigation: Respecting robots.txt rules, implementing polite crawling practices, and managing crawl rates.
Duplicate Pages
- Issue: Websites often have multiple URLs pointing to the same content, leading to duplicate data in the crawl results.
- Impact: Inflated database size and complexity, and potential inaccuracies in data analysis.
- Mitigation: Implementing URL normalization and duplicate content detection algorithms.
Best Practices for Efficient and Ethical Web Crawling
Adhering to best practices is crucial for conducting web crawling activities that are both efficient and respectful of the target websites. Some of the key best practices include:
- Respect robots.txt: Always adhere to the directives provided in the robots.txt file of the target website.
- Implement Polite Crawling: Space out your requests to prevent overloading the server and ensure a positive experience for human users.
- Use a User-Agent String: Clearly identify your crawler with a descriptive user-agent string and provide contact information.
- Handle Redirects Properly: Ensure that your crawler correctly handles redirects to prevent losing data or crawling the same content multiple times.
- Crawl During Off-Peak Hours: If possible, schedule your crawls during times of low traffic to minimize impact on the target website.
Web crawling is a delicate balance between gathering data and respecting the boundaries and resources of the target website. By understanding the challenges involved and adhering to best practices, web crawlers can navigate the web efficiently, ethically, and responsibly, ensuring valuable data collection without compromising the integrity of the web.
Top Web Crawling Best Practices
To ensure a successful and ethical web crawling operation, it’s essential to adhere to established best practices. These practices not only protect the target website’s resources but also enhance the efficiency and effectiveness of your crawling efforts.
Politeness and Crawl Rate
- Description: Politeness in web crawling refers to the practice of minimizing the impact on the target website’s server by controlling the rate at which requests are made.
- Why It’s Important: Overloading a server with too many requests in a short time can slow down or crash the site, negatively affecting its performance for other users.
- Best Practices: Implement rate limiting and adhere to the crawl-delay directive in robots.txt. Additionally, be mindful of the server’s load, and adjust your crawl rate accordingly.
Compliance with Robots.txt
- Description: The robots.txt file is a standard used by websites to communicate with web crawlers and provide guidelines on what parts of the site should not be accessed or crawled.
- Why It’s Important: Respecting the directives in robots.txt ensures ethical crawling and maintains a positive relationship between the crawler and the website owner.
- Best Practices: Always check and comply with the robots.txt file before starting a crawl. If the file disallows crawling certain sections of the site, respect these restrictions.
IP Rotation
- Description: IP rotation involves changing the IP address from which the crawl requests are made at regular intervals.
- Why It’s Important: Some websites may block or limit access to crawlers coming from a single IP address, especially if they make requests at a high rate.
- Best Practices: Use a pool of IP addresses and rotate them to reduce the risk of being blocked or rate-limited. Ensure that the rotation does not violate any terms of service and is done ethically.
Web Crawling vs. Web Scraping: Understanding the Difference
While web crawling and web scraping are terms often used interchangeably, they refer to distinct processes in the realm of data gathering on the internet. Understanding the differences between these two activities is crucial for anyone engaged in data collection and analysis.
Web Crawling
- Definition: Web crawling is the process of systematically browsing the web to collect information about websites and their interconnections. It involves visiting web pages, parsing their content, and following links to other pages.
- Purpose: The primary goal of web crawling is to index the content of websites, making it possible to retrieve information quickly and efficiently. Search engines use web crawlers to gather and update their search index.
- Scope: Web crawling generally covers a broad range of web pages, often aiming to capture the structure of the web or a substantial portion of it.
- Tools and Technologies: Web crawlers rely on automated scripts and bots, with technologies such as Python (with libraries like Scrapy or Beautiful Soup), Java, or C# commonly used for their development.
Web Scraping
- Definition: Web scraping, on the other hand, is the process of extracting specific information from websites. It involves making HTTP requests to web pages, parsing the HTML, and extracting data based on patterns or criteria.
- Purpose: The main aim of web scraping is data extraction for analysis, reporting, or storage. It is often used to gather specific pieces of information, such as product prices, stock levels, or contact details.
- Scope: Web scraping typically focuses on specific web pages or types of content, and is more targeted than web crawling.
- Tools and Technologies: Like web crawling, web scraping can be done using various programming languages and tools, with Python being particularly popular. Libraries such as BeautifulSoup, Selenium, or Puppeteer (for JavaScript) are commonly used.
Ethical Considerations and Legalities
Both web crawling and web scraping must be conducted with ethical considerations in mind. It is essential to respect the robots.txt file of websites, avoid overloading web servers further, and ensure compliance with legal regulations related to data privacy and copyright.
How Web Crawlers Affect SEO and How to Optimize Your Website
The Impact of Web Crawling on SEO
Search Engine Optimization (SEO) is an essential aspect of ensuring your website’s visibility and accessibility. Web crawling plays a pivotal role in SEO, as it directly influences how search engines understand and rank your website.
| Indexing | For your website to appear in search results, it first needs to be indexed by search engines. Web crawling is the initial step in this process, where search engine bots traverse your site, analyze its content, and add it to their index. |
| Content Freshness | Regular and efficient crawling helps in keeping the search engine’s index updated with the latest content from your website, which is crucial for maintaining content freshness and relevance in search results. |
| Site Structure | How your website is crawled can also reflect its structure and hierarchy, impacting how search engines perceive the importance of different pages. A well-structured site is more likely to have its important pages indexed and ranked higher. |
| Technical Issues | Crawlers can also help in identifying technical issues on your site, such as broken links, duplicate content, or accessibility problems, which can negatively impact your SEO if not addressed. |
Optimizing Your Website for Easier Crawling
Ensuring that your website is easily crawlable is a critical component of SEO. Here are some strategies to optimize your site for web crawling:
Using a Sitemap
- Description: A sitemap is a file that provides information about the pages on your site and their relationships.
- Purpose: It aids search engines in understanding the structure of your site, ensuring that all important pages are found and indexed.
- Implementation: Create a comprehensive XML sitemap and submit it through Google Search Console or other search engine webmaster tools.
Improving Website Speed
- Description: The speed at which your website loads affects both user experience and crawl efficiency.
- Purpose: Faster loading times encourage more thorough crawling, as search engine bots can traverse more pages in less time.
- Implementation: Optimize images, utilize browser caching, and leverage content delivery networks (CDNs) to improve load times.
Internal Linking
- Description: This involves linking from one page on your site to another page on the same site.
- Purpose: Effective internal linking helps spread link equity throughout your site and guides crawlers to important pages, enhancing their visibility.
- Implementation: Ensure that important pages are linked to from other relevant pages, using descriptive anchor text.
Configuring Robots.txt
- Description: The robots.txt file provides directives to web crawlers about which parts of your site they should and shouldn’t access.
- Purpose: Proper configuration helps manage crawler access, ensuring efficient use of crawl budget and protecting sensitive content.
- Implementation: Create a robots.txt file with clear and concise directives, and place it in the root directory of your website.
Crawl the Website for Technical Issues With Website Crawler for Technical SEO Analysis
The Website Crawler for Technical SEO Analysis by SiteChecker is a powerful tool designed to navigate and analyze every corner of a website, just as a search engine would. It’s an essential asset for SEO professionals and website owners who want to identify and resolve technical SEO issues that could affect search engine rankings. By crawling a website, this tool efficiently pinpoints areas needing attention, such as broken links, improper redirects, or issues with metadata, ensuring the site’s structure is optimized for search engine visibility and performance.
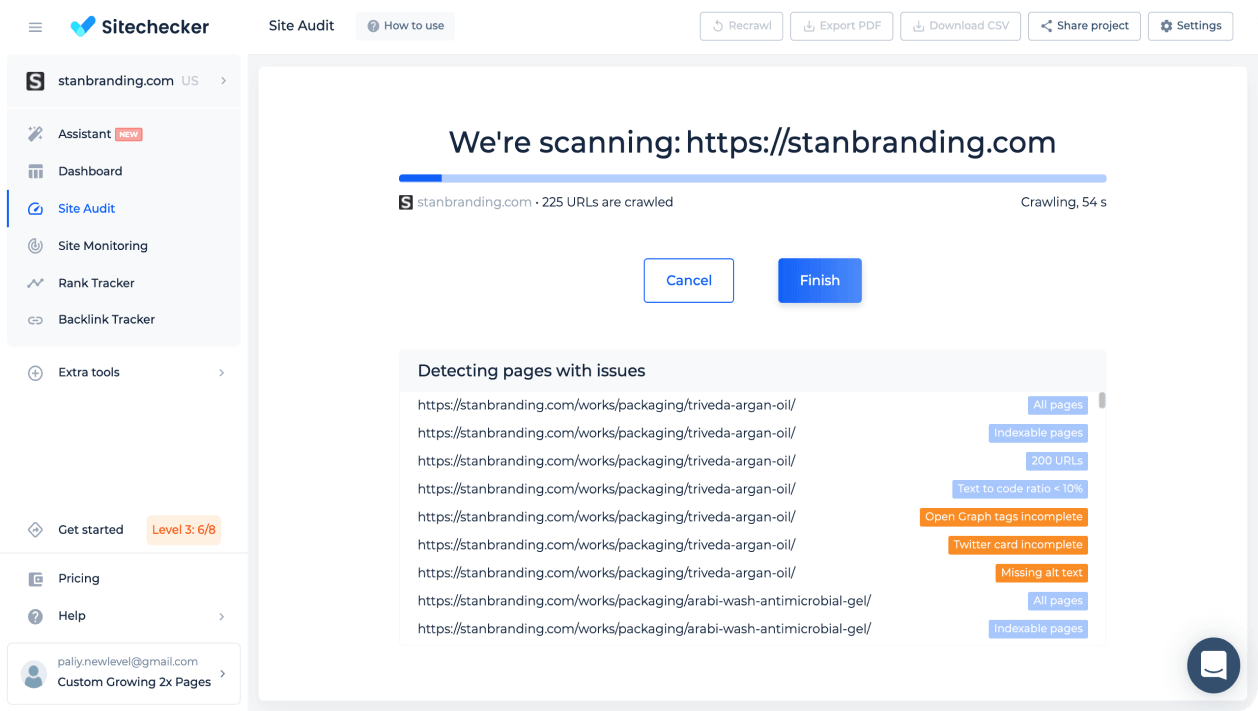
In addition to basic site crawling, the tool offers advanced features that provide a more comprehensive SEO audit. It includes the analysis of page titles, descriptions, and headings for optimization, checks website loading speed, and evaluates mobile responsiveness, all of which are critical components of modern SEO. The tool also generates detailed reports that offer actionable insights and recommendations, making it easier for website owners to understand and implement necessary changes. This level of detailed analysis makes the Website Crawler for Technical SEO Analysis an invaluable tool for maintaining an effective, search engine-friendly website.
Optimize Your Site: Discover SEO Opportunities!
Find and fix hidden technical issues with our comprehensive Website Crawler.
Conclusion
Understanding web crawling is crucial in the digital age, as it forms the backbone of search engine operations and impacts how content is discovered and indexed on the web. This comprehensive guide has navigated through the intricacies of web crawlers, the web crawling process, its applications, and the challenges and best practices associated with it.
We’ve demystified the differences between web crawling and web scraping, shedding light on their distinct purposes and methodologies. Additionally, the guide has provided insights on how to optimize your website for better crawling, emphasizing the significant impact this has on SEO and, consequently, on the visibility of your content online.



