

Le fichier Robots.txt joue un rôle important pour les recherches sur Net, car avant d’examiner les pages de votre site, les moteurs de recherche effectuent une vérification de ce fichier. Grâce à cette procédure, ils peuvent améliorer l’efficacité de la numérisation. De cette façon, ayant bien configuré robots.txt., vous aidez les systèmes de recherche à effectuer l’indexation des données les plus importantes sur vos sites.
Tout comme les directives du générateur de fichiers robots.txt, l’instruction noindex dans les balises meta robots est une simple recommandation pour le robot. C’est la raison pour laquelle ils ne peuvent pas garantir que les pages fermées ne seront pas indexées et incluses dans l’index. Si vous avez besoin de fermer une partie de votre site pour l’indexation, vous pouvez utiliser un mot de passe pour fermer les répertoires.
Syntaxe principale
User-Agent: le robot auquel les règles suivantes seront appliquées (par exemple, “Googlebot”).
Disallow: t les pages que vous voulez fermer pour l’accès (au début de chaque nouvelle ligne, vous pouvez inclure une grande liste de directives).
Chaque groupe User-Agent / Disallow doit être séparée avec une ligne vide. Mais les chaînes non vides ne doivent pas apparaître dans le groupe (entre User-Agent et la dernière directive Disallow).
Hash mark (#) est utilisé pour laisser des commentaires dans le fichier pour la ligne en cours. Tout ce qui est mentionné après la signe dièse sera ignoré. Quand vous travaillez avec un générateur de fichier robot txt, ce commentaire est applicable pour toute la ligne et à la fin de celle-ci après les directives en même temps.
Les catalogues et les noms de fichiers sont sensibles au registre: le système de recherche voit les termes «Catalogue», «Catalogue» et «CATALOGUE» comme différentes directives.
Host: est utilisé par Yandex pour indiquer le site miroir principal. C’est pourquoi si vous effectuez la redirection 301 par page pour coller deux sites, il n’est pas nécessaire de répéter la procédure pour le fichier robots.txt (sur le site dupliqué). Yandex détectera la directive mentionnée sur le site qui doit être bloqué.
Crawl-delay: vous pouvez limiter la vitesse de votre site, ce qui est très utile si celui-ci est fréquemment visité. Cette option est activée pour protéger le générateur de fichiers de ce type des problèmes avec le chargement supplémentaire de votre serveur. Cela est causé parce que divers systèmes de recherche traitent les informations sur les sites.
Regular phrases: pour fournir des paramètres de directives plus flexibles, vous pouvez utiliser deux symboles mentionnés ci-dessous:
* (étoile) – signifie toute séquence de symboles,
$ (signe de dollar) – signifie la fin de la ligne.
Les cas principaux de l’utilisation du générateur robots.txt
Pour interdire l’indexation complète du site
Agent utilisateur: *
Disallow: /Cette instruction est appliquée quand vous créez un nouveau site et utilisez des sous-domaines pour y accéder.
Très souvent, en créant un nouveau site, les développeurs Web oublient de fermer une partie de celui-ci pour l’indexation et, par conséquent, les systèmes d’index en traitent une copie. Si une telle erreur a eu lieu, votre master domain est soumis à la redirection 301 par page. N’oubliez pas de test redirections de page de temps en temps. Le générateur Robot.txt est très utile!
La construction suivante PERMET d’indexer l’ensemble du site:
User-agent: *
Disallow:
L’interdiction d’indexation d’un dossier particulier
User-agent: Googlebot
Disallow: /no-index/
L’interdiction pour certains robots de recherche de visiter la page
User-agent: Googlebot
Disallow: /no-index/this-page.html
L’interdiction d’indexation de certains types de fichiers
User-agent: *
Disallow: /*.pdf$
Pour permettre à certains robots Web de visiter une page déterminée
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Website lien à sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Si vous remplissez en permanence votre site avec un contenu unique il y a quelques particularités à prendre en compte lors de l’utilisation de cette directive:
- n’ajoutez pas de lien dans votre sitemap dans le générateur de fichier robots.txt
- choisissez un nom non-standartisé pour le plan du site de sitemap.xml (par exemple, my-new-sitemap.xml, puis ajoutez ce lien aux systèmes de recherche à l’aide des webmasters).
Le fait est que beaucoup de webmasters malhonnêtes analysent le contenu des autres sites et l’utilisent pour leurs propres projets.
Vérifiez le statut d'indexation des pages de votre site Web Détecter toutes les URL noindexed et savoir quelles pages du site sont autorisées à être explorées par les robots des moteurs de recherche
Quelle méthode est meilleure: le générateur de robots.txt ou noindex?
Si vous ne voulez pas certaines pages d’être indexées, on recommande noindex dans la balise meta robot. Pour l’implémenter, vous devez ajouter la méta-balise suivante dans la section de votre page:
<meta name=”robots” content=”noindex, follow”>En utilisant cette approche, vous pouvez:
- éviter l’indexation de certaines pages lors de la prochaine visite du robot (il ne sera pas nécessaire de supprimer la page manuellement en utilisant les webmasters);
- gérer pour transmettre le jus de référencement de votre page.
En outre, le générateur de fichiers robots.txt sert mieux pour fermer ces types de pages:
- les pages administratives de votre site;
- les données de recherhces sur le site;
- pages d’enregistrement / autorisation / réinitialisation du mot de passe.
Quels outils vous aident à analyser le fichier robots.txt?
En créant ces fichiers, vous devez vérifier s’ils ne contiennent pas des erreurs. Pour cela vous pouvez utiliser la vérification par les systèmes de recherche:
Connectez-vous au compte avec le site confirmé sur sa plate-forme, passez à Crawl, puis à Robot.txt Tester.
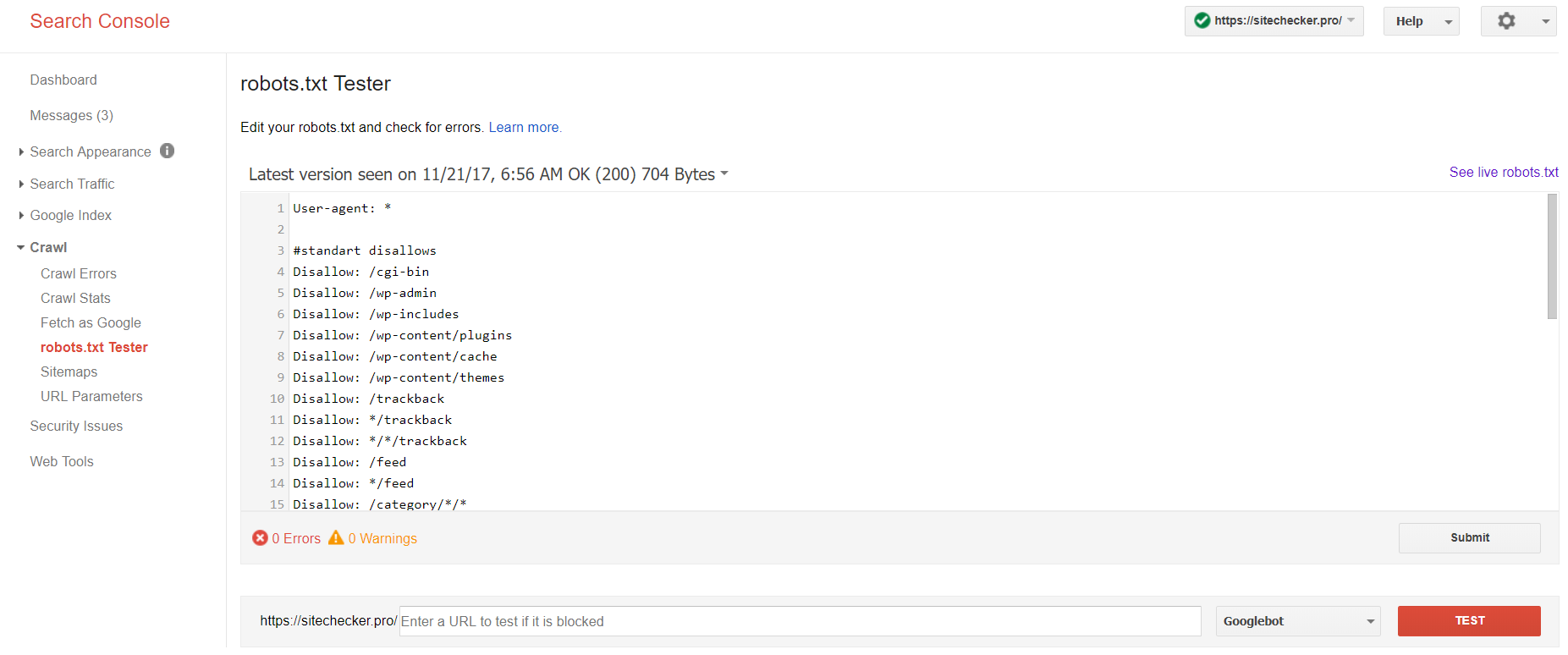
Ce test de robot txt vous permet de:
- détecter toutes vos erreurs et tous les problèmes existants;
- vérifier les erreurs et faire les corrections nécessaires pour installer ensuite le nouveau fichier sur votre site sans aucune vérification supplémentaire;
- examiner si vous avez bien fermé les pages que vous ne voulez pas d’être indexées et si celles qui doivent être soumises à l’indexation sont ouvertes.
Connectez-vous au compte avec le site confirmé sur sa plate-forme, passez à Outils, puis à l’analyse Robots.txt.
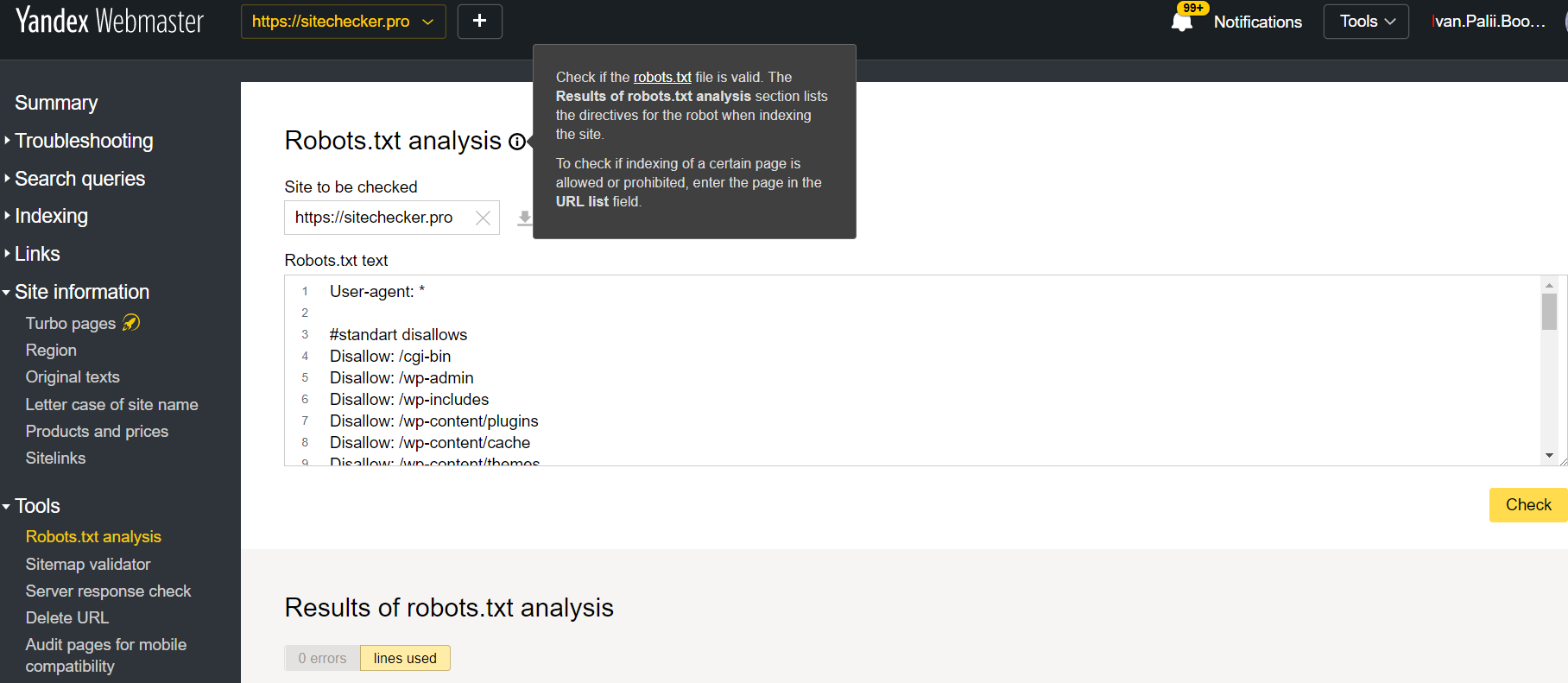
Ce testeur propose presque le même analyse que le précédent. La différence n’est que:
- ici vous n’avez pas besoin d’autoriser et de prouver les droits pour un site, il y a une vérification immédiate de votre fichier;
- il n’est pas nécessaire d’insérer par page: il est possible de vérifier la liste complète des pages en une seule session
- vous pouvez vous assurer que Yandex a bien identifié vos instructions.



