Es probable que ya conozcas el SEO y sus buenas prácticas: el valor de la estructura de un sitio web, las reglas para etiquetar, keyword stuffing, el valor del contenido único y otras tantas cosas a poner en práctica. Si es así, entonces de seguro ya has oído hablar de Google bots. Sin embargo, ¿qué tanto sabes de Google bots?
Este fenómeno difiere de la popularmente conocida optimización SEO, ya que se ejecuta en un nivel más profundo. Si una optimización SEO trata de optimizar un texto para la búsqueda en los buscadores, entonces Gooogle Bot es un proceso de optimización para las Google Spiders. Por supuesto, estos procesos tienen similaridades, pero permítenos dejar clara su gran diferencia, ya que esta puede influir profundamente en tu sitio web. Aquí hablaremos del fenómeno de hacer “crawling” en un sitio web, ya que este es el asunto principal al que todos debemos prestar atención si hablamos de la “buscabilidad” de un sitio web.
Tabla de Contenidos
- ¿Qué es Googlebot?
- 6 estrategias acerca de cómo optimizar tu sitio web para el rastreo (crawling) de Googlebot
- ¿Cómo analizar la actividad de Googlebot?
¿Qué es Googlebot?
Los rastreadores de sitios webs (también llamados crawlers) son bots o robots que examinan una página web y crean un índice. Si una página web permite acceso a un robot, entonces este bot añade esta página a su índice, y solo entonces esta página se vuelve accesible para los usuarios. Si deseas ver cómo se ejecuta este proceso, mira esto. Si deseas entender el proceso de optimización de Googlebot, necesitas reconocer exactamente cómo es que una Google Spider escanea un sitio web. Aquí están los cuatro pasos.
Sí una página web tiene alto nivel en el ranking, Google Spider empleará más tiempo en el rastreo
Aquí es donde podemos hablar del “Crawl Budget”, qué es el tiempo exacto que un robot pasa escaneando un determinado sitio: a mayor autoridad, mayor presupuesto recibirá.
Los Google Robots rastrean un sitio web constantemente
He aquí lo que Google dice al respecto: “Los Google robots no tiene que acceder a un sitio web más de una vez por segundo”. Lo que significa que tu sitio web esta bajo el control constante de Google Spiders si es necesario que estas entren al mismo. Hoy en día muchos managers y especialistas SEO debaten sobre el llamado “ritmo de rastreo” y trata de encontrar una manera optima que el rastreo de un sitio web se haga a un buen nivel de rankeo. Sin embargo, aquí podríamos estar hablando de una mala interpretación, ya que el “ritmo de rastreo” no es más que la velocidad del robot de Google tratando de alcanzar una petición de rastreo. Incluso es posible modificar este ritmo por nosotros mismos con una herramienta de Webaster. Un gran número de backlinks (o enlaces entrantes), singularidad y menciones en redes sociales influencian tu posición en la búsqueda de resultados. También debemos destacar que estas Spiders no rastrean constantemente cada página. Por lo tanto, las estrategias de contenido constante son muy importantes, tal y como el contenido único y de valor atrae la atención de los bots.
Archivos Robots.txt son lo primero que los robots de Google escanean para tener un mapa de rastreo del sitio
Esto significa que si una página tiene marcada como “No permitido” este archivo, los robots no podrán escanearla ni indexarla.
XML Sitemap es una guía para los Googlebots
XML Sitemap ayuda a los robots a encontrar que lugar de los sitios web debe ser rastreado e indexado. Como puede haber diferencias en la estructura u organización de un sitio web este proceso no es automatizado. Un buen Sitemap puede ayudar a las páginas con un ranking bajo, pocos backlinks y contenido inservible, ya que esto ayuda a Google con las imágenes, videos, noticias, entre otros.
6 estrategias acerca de cómo optimizar tu sitio web para el rastreo (crawling) de Googlebot
Tal y como ya has entendido, las mejoras hechas a Google Spider deben darse antes que cualquier paso en SEO. Así pues, ahora consideraremos lo que deberías hacer para facilitar el proceso de indexación para los Google bots.
Exagerar no es bueno
De seguro sabes que los Googlesbots no pueden escanear varios marcos de escritura. Tales como Flash, JavaScript, DHTML y el archiconocido HTML. Por otro lado, Google no ha aclarado si Googlebot puede rastrear Ajaz y JavaScript, así que es mejor no usarlos al momento de crear tu sitio web.
Aunque Matt Cutts dice que JavaScript puede ser abierto por las Spiders, tales declaraciones del Webmaster de Google pueden ser refutadas por esto: “Si elementos como las cookies, en marcos como Flash y JavaScript, no pueden ser vistos en el visualizador de textos, entonces el sitio web no podrá ser rastreado. Ante mis ojos, no se debe abusar de JavaScript.
No subestimar los archivos robots.txt
¿Alguna vez has pensado en el propósito de los archivos robots.txt? Es un archivo muy común utilizado en las estrategias SEO, ¿pero es realmente útil? Primero que nada, este archivo es una directriz para todos los crawlers, para lograr que los robots de Google inviertan algo de “crawl budget” en tu sitio web. Segundo, tú mismo debes indicar que archivos den escanear los robots, por lo que si algún archivo no puede ser rastreado, puedes indicarlo en tu robots.txt. ¿Para qué hacer esto? Si hay alguna página que no debe ser rastreada, el robot vera esto y pasará a escanear una parte de tu sitio que sea más importante. No obstante, mi sugerencia es no bloquear lo que no debe ser bloqueado. Si no indicas que algo no debe ser rastreado, el bot rastreará e indexará todo por defecto. La función principal del archivo robots.txt es indicarle al robot a donde no debe ir.
El contenido y de valor realmente importa
La regla es que el contenido que es rastreado constantemente, recibe más tráfico como resultado. A pesar de que el rango de una página determina los rastreos frecuentes, este puede hacerse a un lado cuando se trata de utilidad y frescura en páginas con un rango similar. Por lo tanto, tu objetivo principal es que las páginas con un ranking bajo sean escaneadas con más frecuencia. AJ Kohn dijo una vez: “Eres un ganador si has transformado una página con una posición baja en el raking, en una de esas que son escaneadas más a menudo que las de la competencia.”
Obteniendo desplazamientos mágicos en la página
Si tu sitio contiene una cantidad interminable de “scroll pages” (desplazamientos), eso no significa que no tienes posibilidades de optimizarlo para Googlebot. No obstante, debe asegurarte que este tipo de sitios web cumplan con los requerimientos de Google.
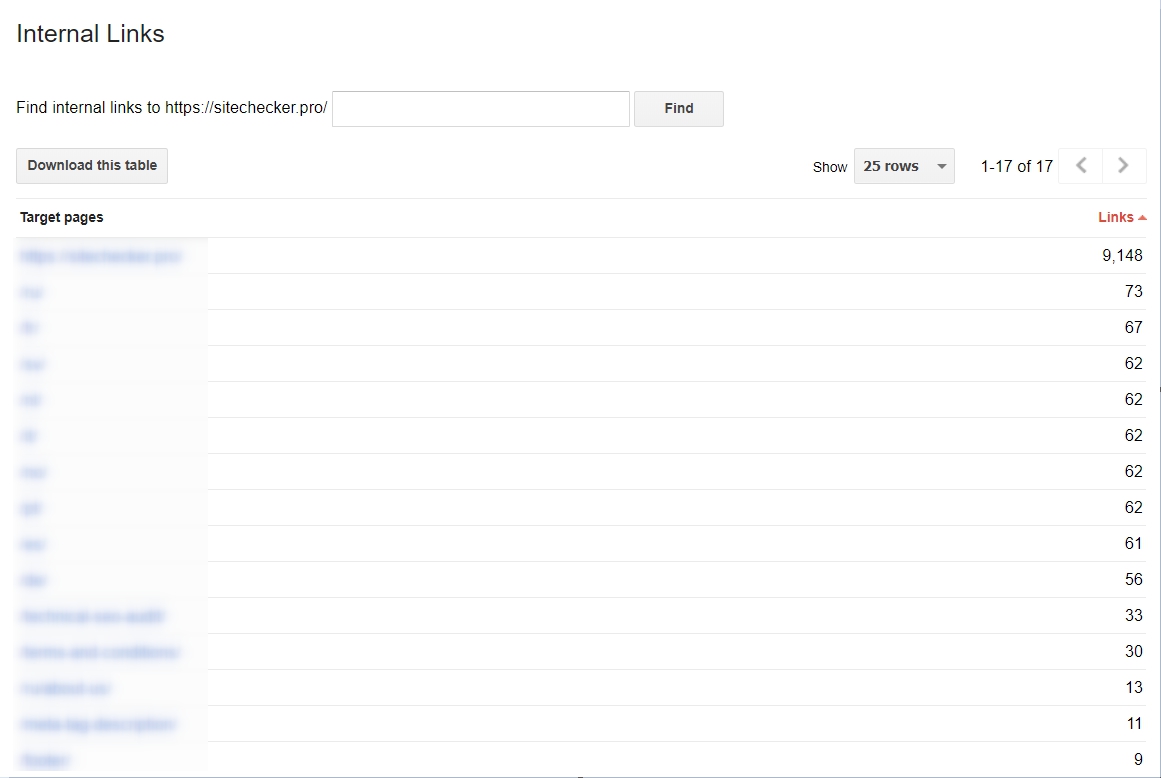
Debes comenzar a usar links internos
Esto es muy importante si deseas hacer más sencillo el proceso de escaneo de los Googlebots. Si tus enlaces están “apretados” y son consolidados, el proceso de escaneo será mucho más efectivo. Si deseas un análisis de los hipervínculos internos de tu sitio web, puedes hacerlo con las herramientas Webmaster de Google, entonces ve a la sección de “Search Traffic” y allí seleccionas “Enlaces Internos”. Si las páginas web están al tope de la lista, entonces estas tienen contenido útil.
Sitemap.xml es vital
El Sitemap ofrece directrices para el Googlebot acerca de la manera en la cual escanear un sitio web; es algo tan sencillo como un mapa. ¿Entonces par que usarlo? Muchos sitios web no son fáciles de escanear, estas dificultades hacen que el proceso de rastreo o crawling sea más complicado. Es por eso que las secciones de un sitio web pueden confundir a los Google Spiders, pero el archivo Sitemap asegura que todo el sitio web sea rastreado.
¿Cómo analizar la actividad de Googlebot?
Si deseas ver la actividad que ejecuta Googlebot en tu espacio, utiliza las herramientas de Google. Incluso, aconsejamos revisar los datos proporcionados de manera periodica, ya que estos muestran problemas comunes ocurridos en el proceso de rastreo. Sólo mira la sección de “Crawl” en la herramienta de Webmaster.
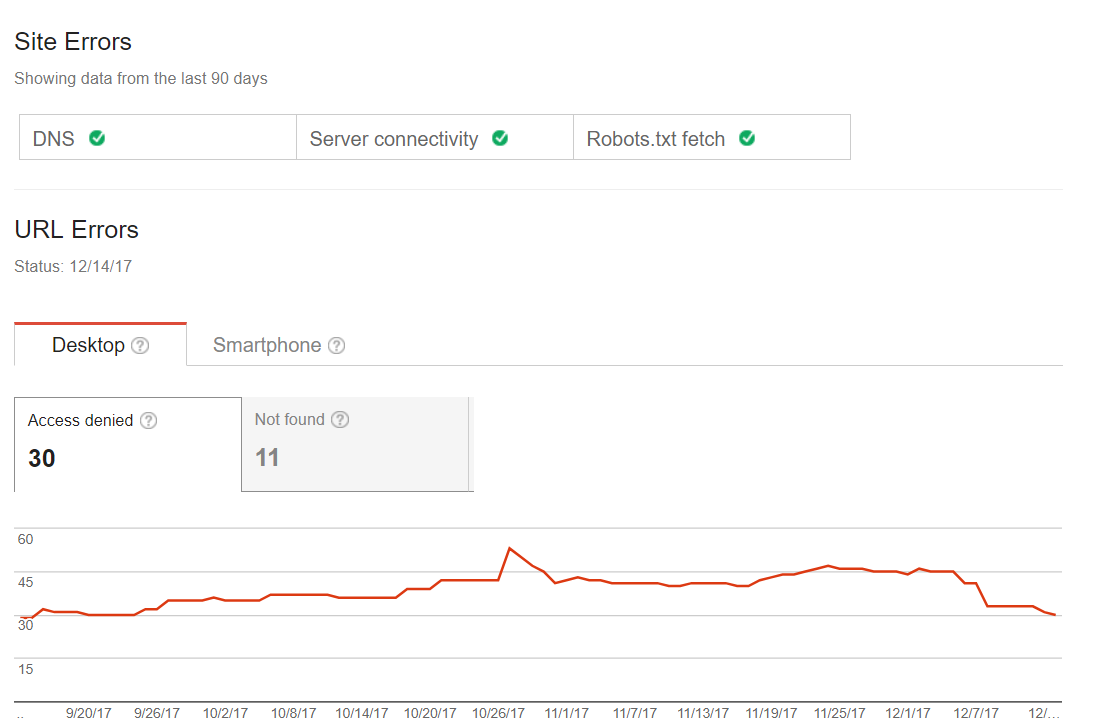
Errores comunes de rastreo
Puedes chequear si tu sitio web enfrenta algún tipo de problema durante el proceso de escaneo. Por lo tanto, no tendrás problemas con el estatus de la página o alguna bandera roja (por ejemplo, una página que sea mandada al último lugar de la indexación). Ese es el primer paso que debes dar cuando hablamos de una optimización de Googlebot. Algunos sitios web pueden tener problemas menores en el escaneo, pero eso no significa que esto influenciará el tráfico o el ranking. Sin embargo, con el paso del tiempo estos problemas terminaran con una baja de tráfico. Aquí puedes encontrar un ejemplo de un sitio como ese:
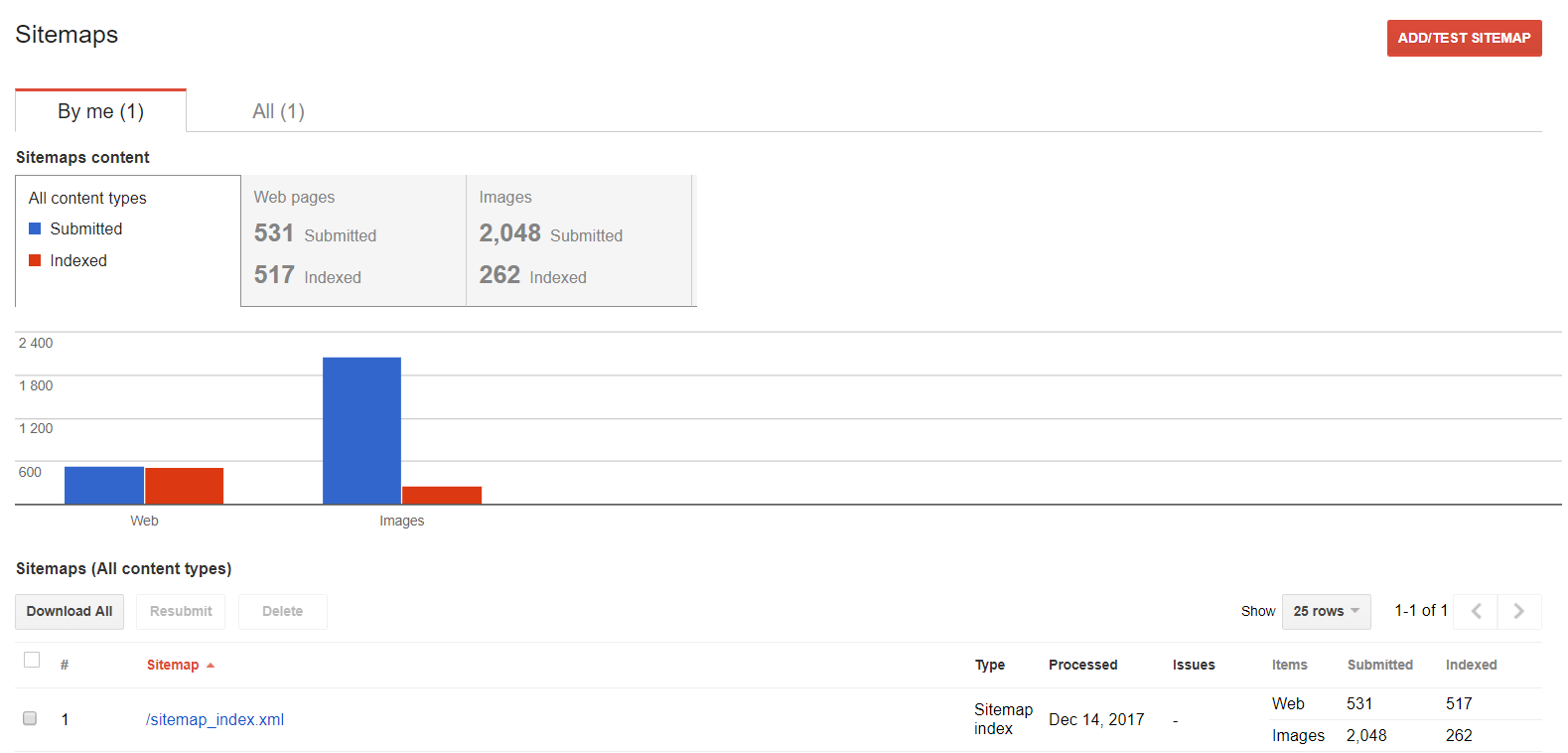
Sitemaps
Puedes usar esta función si deseas trabajar en tu Sitemap: examinar, añadir o saber que contenido está siendo indexado.
Atracción
La sección “Fetch as Google” te ayuda a ver tu sitio o pagina de la manera en la que la ve Google.
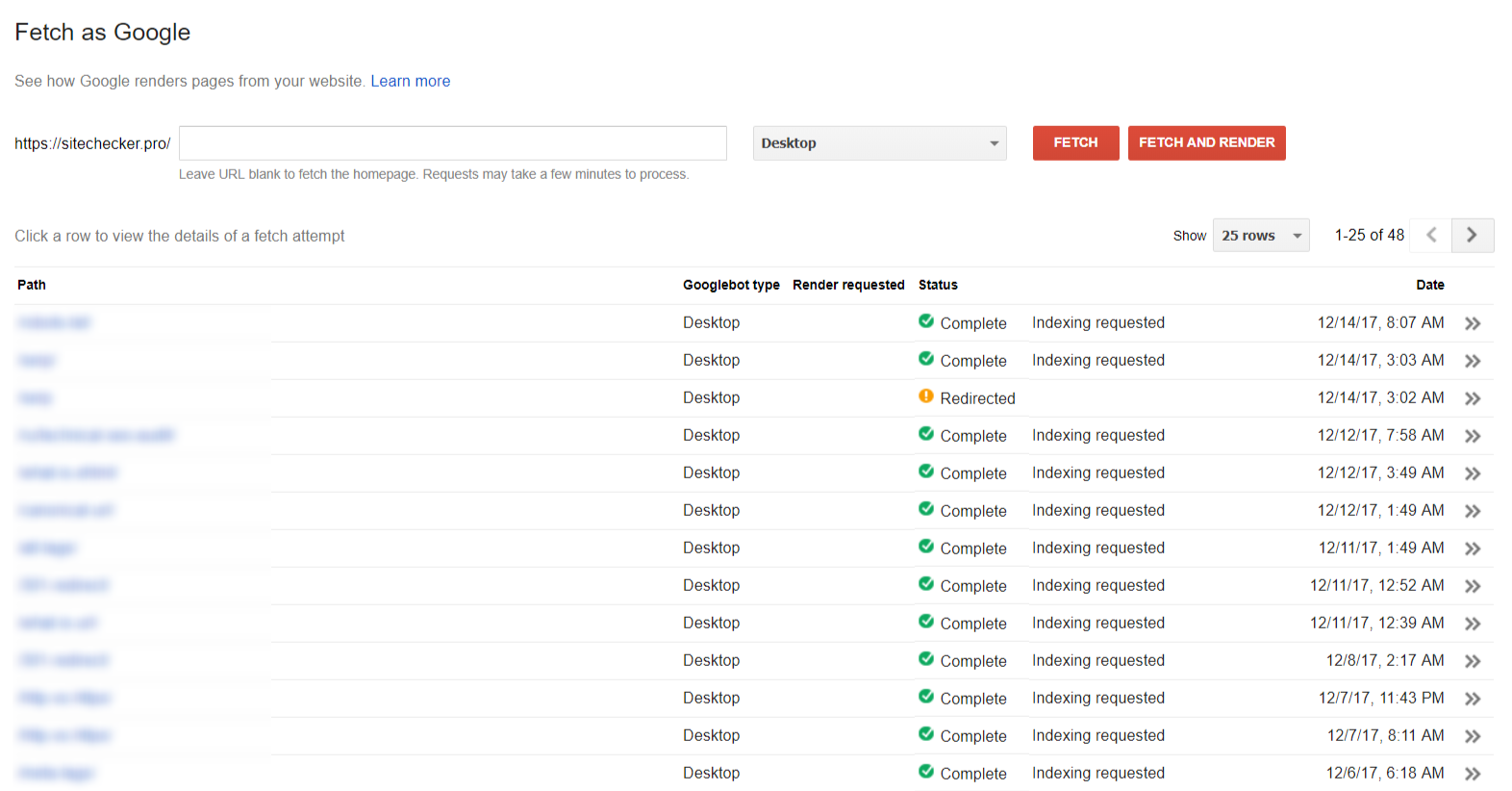
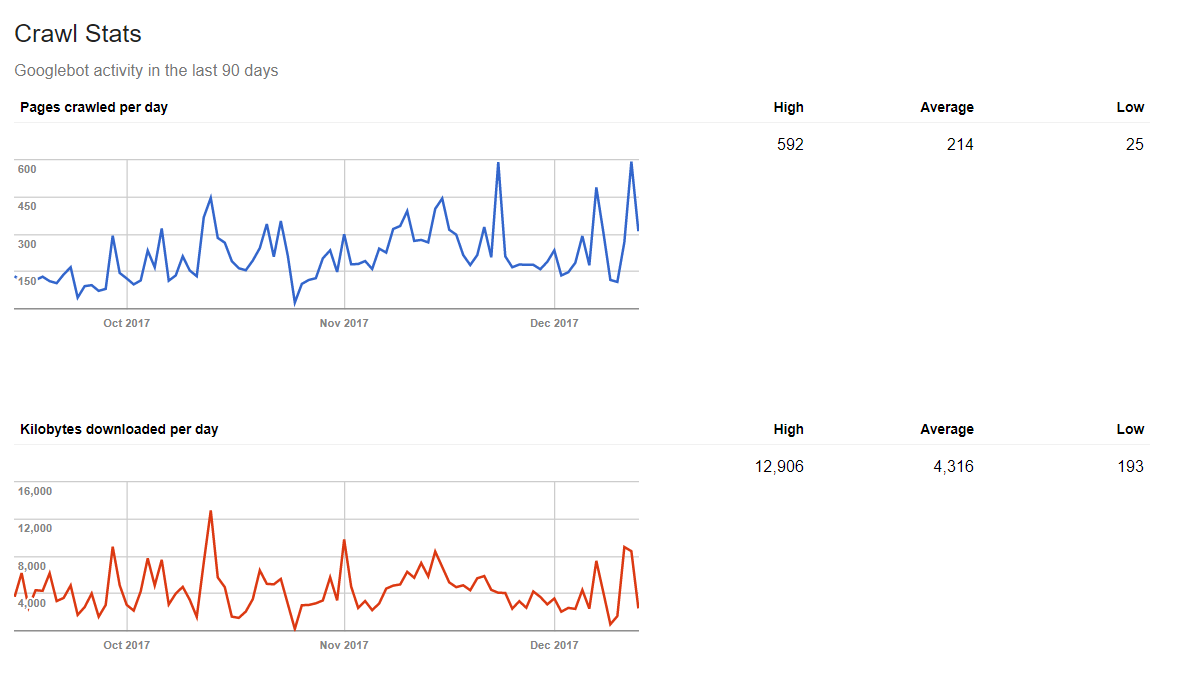
Estadísticas de crawling (rastreo)
Google también puede decirte cuanta data ha procesado un Google Spider en un día. Por lo que si publicas contenido nuevo contantemente, tendrás resultados positivos en las estadísticas.
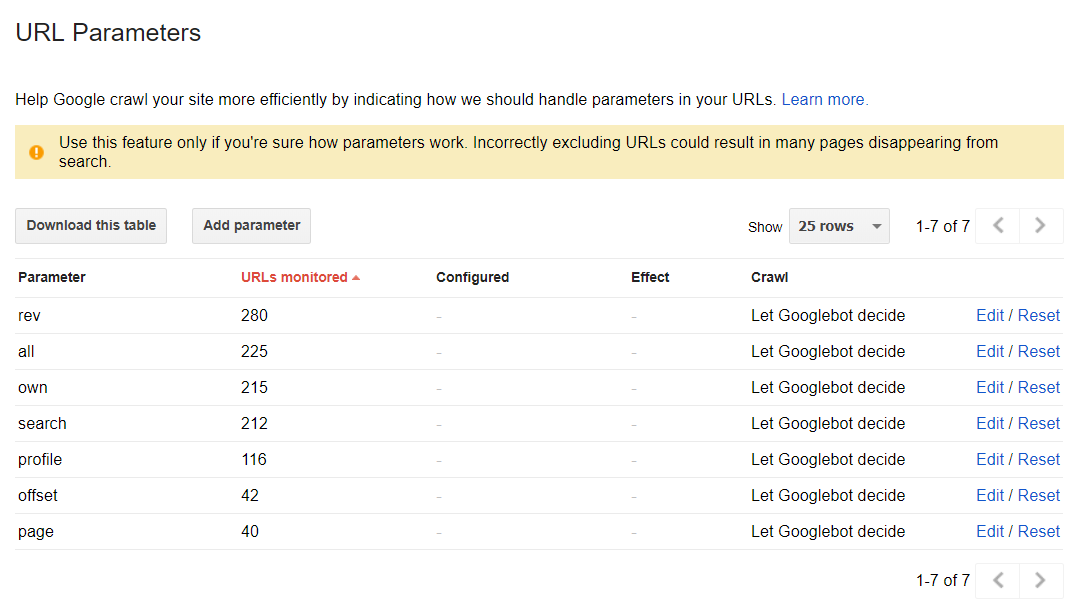
Los parámetros URL
Esta sección puede ayudarte a descubrir la manera en la que Google indexa tu sitio web usando parámetros URL. Sin embargo, a modo de default, todas las páginas son indexadas según la decisión de las arañas.