Waarschijnlijk ben je op de hoogte van SEO en hoe dit het best ingezet kan worden: de waarde van de structuur van de website, de regels bij het gebruik van tags, zoekwoorden gebruiken, de waarde van unieke content optimalisatie en misschien heb je zelfs gehoord van de Google bots. Maar wat weet je van de Google bots eigenlijk?
Dit fenomeen gaat verder dan de bekende SEO optimalisatie, omdat het op een volledig ander level plaatsheeft. Als SEO optimalisatie gaat over het optimaliseren van een tekst voor zoekmachine aanvragen, dan is de Google bot een proces van websiteoptimalisatie voor de Google spiders. Deze processen hebben gelijkende onderdelen, maar laat ons eerst het verschil uitleggen omdat dit veel te maken heeft met jouw website. Hier gaat het om hoe goed jouw website gecrawld kan worden, wat het belangrijkste onderdeel is wanneer het gaat om de vindbaarheid van een website.
Inhoudsopgave
- Wat is Googlebot?
- 6 strategieën om jouw website te optimaliseren voor crawling door Googlebot
- Hoe analyseer je de activiteit van Googlebot?
Wat is Googlebot?
Website crawlers of Google bots zijn robots die een webpagina bekijken en een index creëren. Wanneer een webpagina de bot toegang verleent, dan voegt de bot de pagina aan de index toe, zodat deze toegankelijk wordt voor gebruikers. Wanneer je wilt weten hoe dit proces verloopt, klik dan hier. Wil je weten hoe het proces van Googlebot optimalisatie verloopt, dan moet je eerst weten hoe een Google spider een website scant. Hier zijn de vier stappen:
Heeft een webpagina een hogere page ranking level, dan besteedt de Google Spider meer tijd aan het crawlen.
Hier gaat het om ‘Crawl budget’, wat de exacte tijd is die door web robots gebruikt wordt bij het scannen van een bepaalde website: heeft de pagina een hogere autoriteit, dan wordt er meer budget besteedt.
Google robots crawlen een website constant
Dit is wat Google hierover zegt: ‘Google robot hoeft niet vaker toegang te hebben tot een website dan eens per seconde.’ Dat betekent dat de website onder constant toezicht van de web spiders staat wanneer zij toegang nodig hebben. De SEO-managers van vandaag hebben het over de crawl ratio en proberen de optimale manier te vinden voor website crawling om zo op een hoger leven te komen. We kunnen dit zien als een verkeerde interpretatie van de crawl ratio, aangezien dit niets meer is dan de snelheid van de aanroepen van de Google robot, in plaats van constante herhaling. Je kunt de ratio zelf bijstellen door Webmaster Tools te gebruiken. Een groot aantal backlinks die kunnen worden gecontroleerd met de backlink checker, unieke inhoud en sociale activiteit beïnvloeden uw positie in de zoekresultaten. Hier moet ik bij vermelden dat de web spiders niet alle pagina’s constant scannen, daarom zijn constante content strategieën rond unieke en bruikbare content belangrijk, want die trekken de aandacht van de bot.
Robots.txt file is het eerste dat de Google robots scannen om zo een wegbeschrijving te krijgen voor het crawlen van de website
Dit betekent dat een pagina die in deze file ontoegankelijk genoemd wordt, niet meegenomen kan worden door de robots voor het scannen en indexeren.
XML sitemap is een gids voor Google bots
XML-sitemap helpt de bot om te bekijken welke plaatsen op de website gecrawld en geïndexeerd moeten worden, want aangezien er verschillen kunnen zijn tussen de structuur en organisatie van de website, kan dit niet automatisch gedaan worden. Een goede sitemap helpt de pagina’s met een lager ranking level, weinig backlinks en waardeloze inhoud, en helpt Google ook om afbeeldingen, nieuws en video’s beter te herkennen.
6 strategieën om jouw website te optimaliseren voor crawling
Zoals je begrijpt, moet optimalisatie voor de Google spiders gedaan worden voordat er stappen gezet worden in zoekmachineoptimalisatie. Laten we daarom eens kijken naar wat je moet doen om de Google bots te helpen bij het indexeren.
Overdaad is niet goed
Weet je dat Googlebots verschillende frames niet kunnen scannen, zoals Flash, JavaScript, DHTML net als HTML? Daarnaast is er nog steeds geen opheldering of de Googlebot Ajax en JavaScript kan crawlen en daarom is het beter om deze niet te gebruiken wanneer je een website opzet. Hoewel Matt Cutts stelt dat JavaScript geopend kan worden voor web spiders, laat de Google Webmasters Handleiding iets anders zien:’ Wanneer elementen zoals cookies, verschillende frames, Flash of JavaScript niet gezien kunnen worden in een tekstbrowser, dan is het mogelijk dat de web spiders de pagina niet kunnen crawlen.’ Daarom is overmatig gebruik van JavaScript niet verstandig.
Onderschat de robots.txt file niet
Heb je ooit stilgestaan bij het nut van de robots.txt file? Het is een file die vaak gebruikt wordt bij het opzetten van een SEO strategie, maar is het echt wel handig? Allereerst, deze file is een directief voor alle web spiders, de Google robot spendeert het crawl budget op alle website van jouw website. Daarnaast bepaal je zelf wat de bots kunnen scannen, dus wanneer je niet wilt dat een bepaalde site meegenomen wordt, geef je dit aan in de robots.txt file. Waarom zou je dit doen?
Google ziet op deze manier direct dat bepaalde pagina’s niet meegenomen moeten worden en scant het deel van de website dat wel belangrijk is voor jou. Mijn advies is echter om niet af te blokken wat niet afgeblokt moet worden. Wanneer je niet aangeeft dat iets niet gecrawld oet worden, crawlt de bot dit en wordt het in de index opgenomen. Het nut van de robots.txt file is dus aangeven waar je niet wilt dat de bot aan het werk gaat.
Bruikbare en unieke content is echt belangrijk
De regel is dat content die vaak gecrawld wordt, meer bezoekers zal generen. Ondanks het feit dat PageRank de frequentie van het crawlen bepaalt, kan het opzij geschoven worden wanneer het gaat om bruikbaarheid en versheid van de pagina’s die dezelfde PageRank hebben. Jouw doel is dus om de pagina’s die minder goed ranken, vaker gescand te krijgen. AJ Kohn zei ooit: ‘Je bent een winnaar wanneer jouw lager gerankte pagina’s veranderd zijn in pagina’s die meer gescand worden dan die van de concurrent.’
Magische scroll pagina’s verkrijgen
Wanneer jouw website pagina’sheeft waarop je eindeloos moet scrollen, dan betekent dit niet dat je geen kansen hebt bij Googlebot optimalisatie. Je moet er alleen voor zorgen dat deze webpagina’s in overeenstemming zijn met de handleiding van Google.
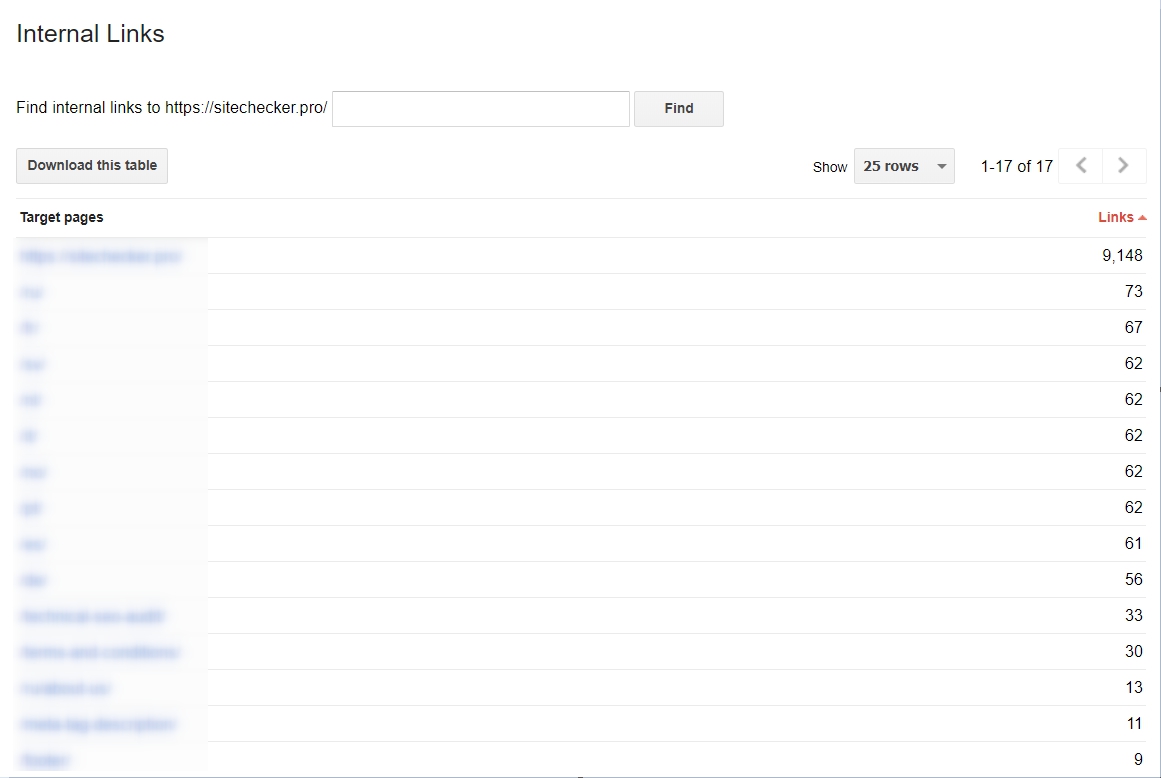
Je kunt beginnen met interne links
Dit is erg belangrijk wanneer je het proces van het scannen makkelijker wilt maken voor de Googlebots. Wanneer jouw links schoon zijn en duidelijk, dan is het proces van het scannen een stuk makkelijker. Wil je een analyse hebben van jouw interne hyperlinks, dan kun je dit gewoon doen in de Google Webmaster Tool, dan Search Traffic en kies vervolgens Internal Links. Wanneer de webpagina’s hoog in de lijst staan, bevatten deze veel waardevolle content.
Sitemap.xml is vitaal
De sitemap geeft de richting aan voor de Googlebot bij het openen van een website: het is een simpele kaart die gevolgd kan worden. Waarom wordt het gebruikt? Veel websites vandaag de dag zijn niet gemakkelijk te scannen, en deze moeilijkheden kunnen het proces van crawlen erg ingewikkeld maken. Daarom worden de secties van de website die verwarrend kunnen zijn opgenomen in een sitemap, zodat je zeker weet dat alle gebieden van de website gecrawld worden.
Hoe analyseer je de activiteit van de Googlebot?
Wil je weten wat de Googlebot op jouw wbesite gedaan heeft, dan kun je Google Webmaster Tools gebruiken. Ik adviseer je om deze data regelmatig te controleren, omdat je de fouten kunt zien die tegengekomen zijn bij crawling. Check de ‘Crawl’ sectie in de Webmaster Tools.
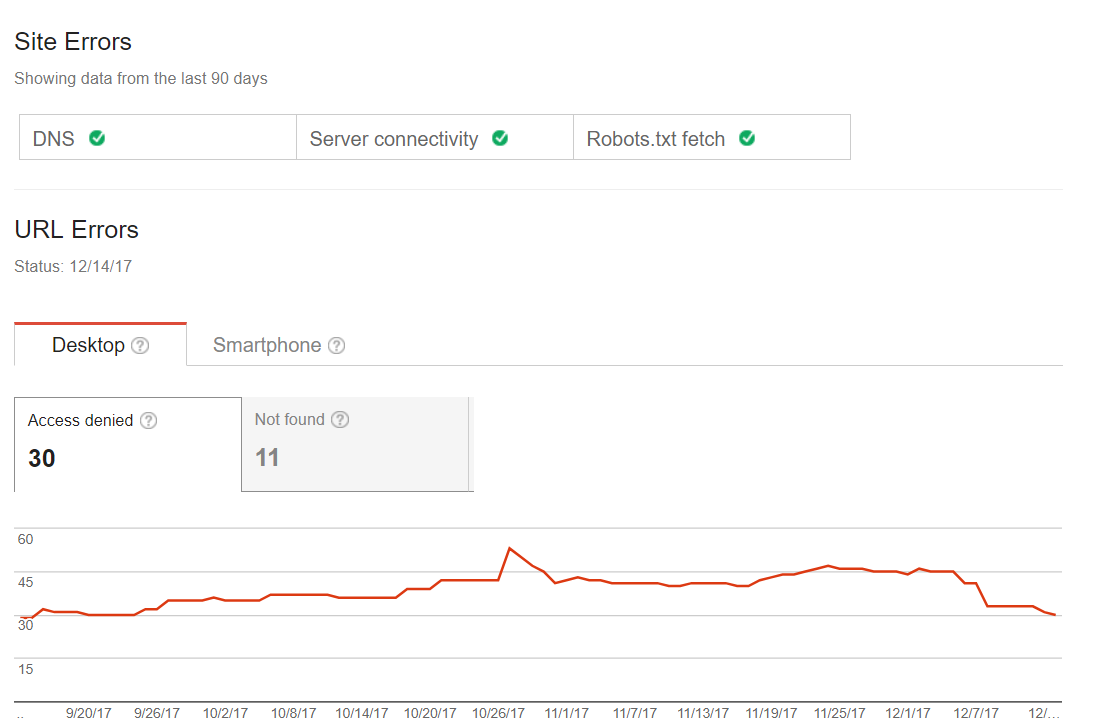
Veel voorkomende crawling errors
Je kunt zien wanneer jouw website problemen getoond heeft tijdens het proces van het scannen. Je kunt geen statusproblemen hebben, of rode vlaggen die aangeven dat een pagina problemen heeft aan de hand van de laatste index. De eerste stap die je moet zetten wanneer het om Googlebot optimalisatie gaat. Sommige website hebben kleine scanfouten, maar dat betekent niet dat dit invloed heeft op verkeer of ranking. Maar wanneer de tijd verstrijkt, kunnen deze problemen alsnog zorgen voor terugloop in het verkeer. Hier vind je een voorbeeld van zo’n website:
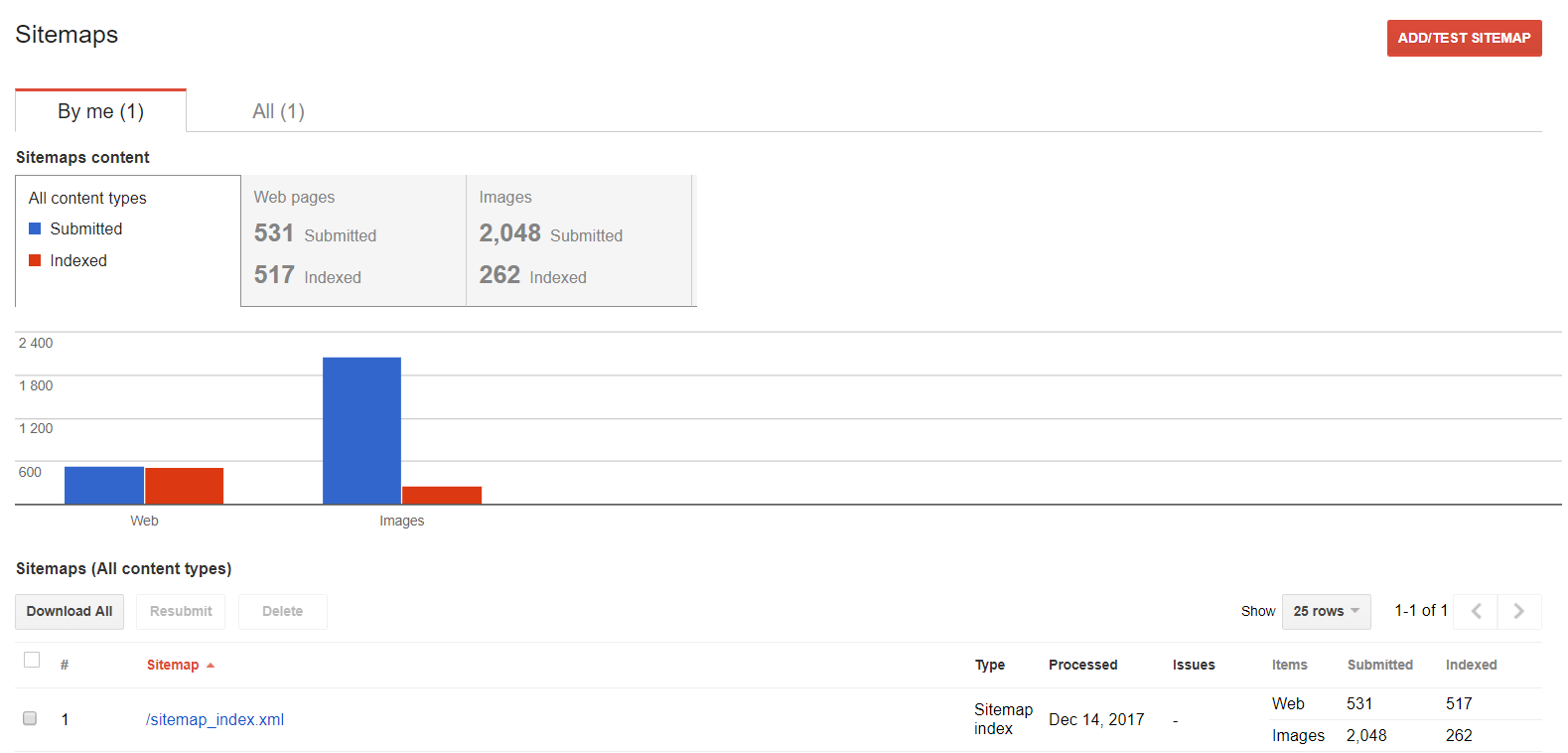
Sitemaps
Deze functie kun je gebruiken wanneer je met je sitemap wilt werken: inspecteer, voeg toe of ontdek welke content geïndexeerd wordt.
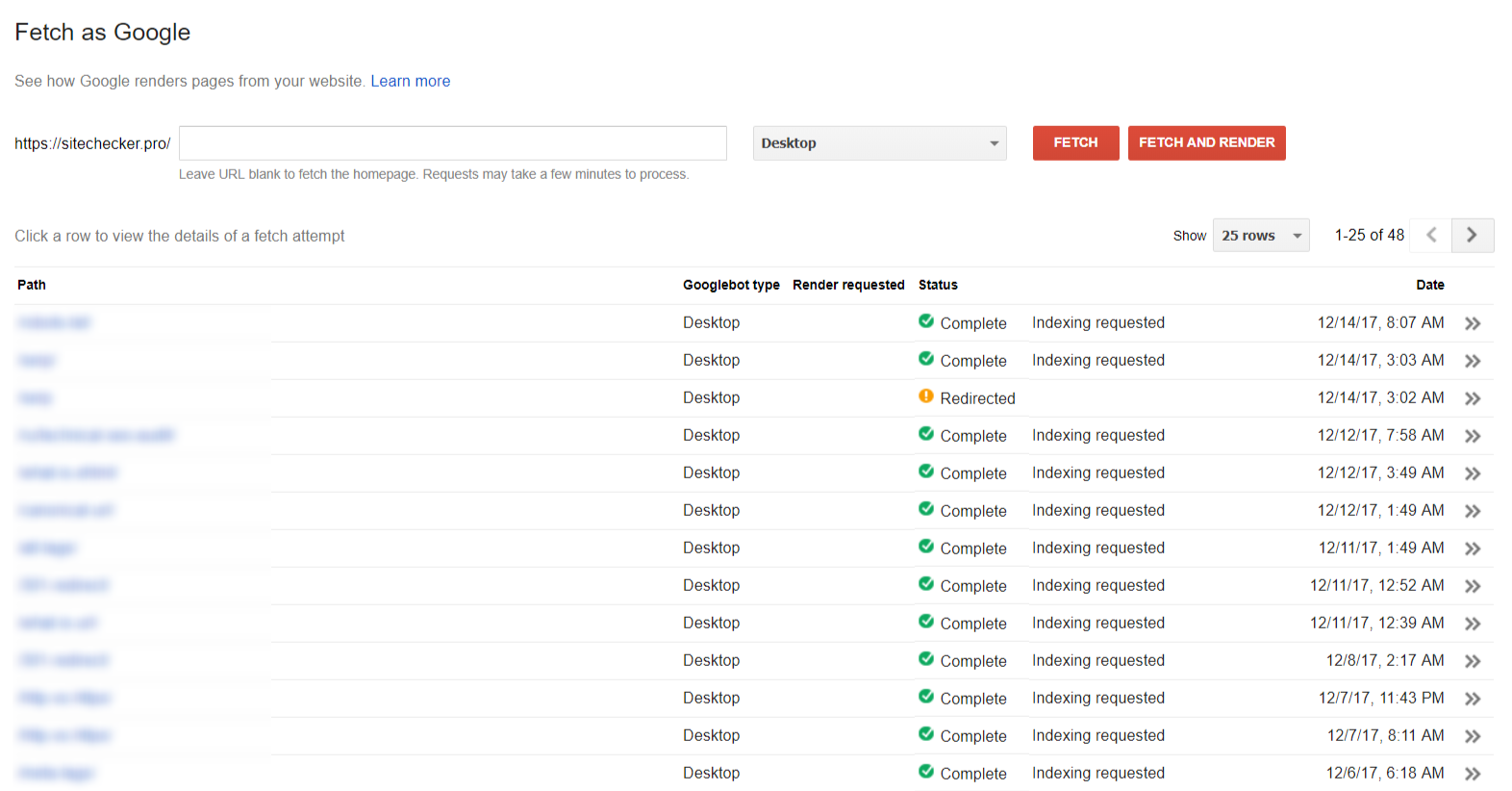
Fetching
De sectie “Fetch as Google” helpt je om jouw website of pagina te zien zoals Google deze ziet.
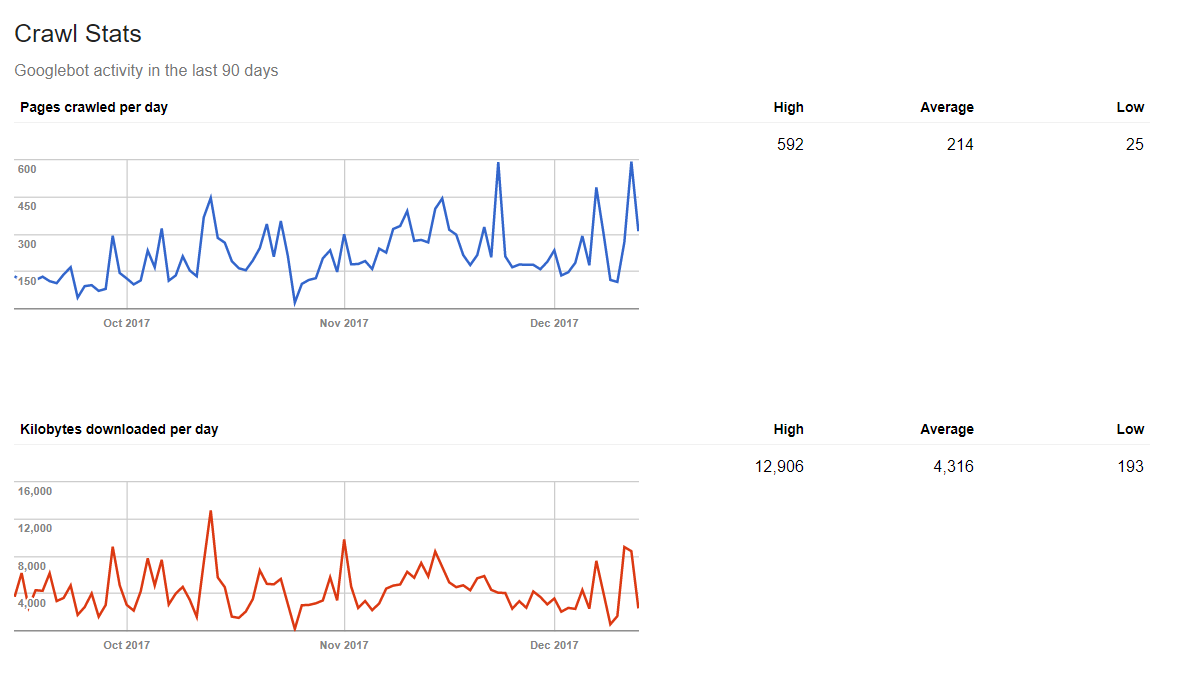
Crawling statistieken
Google kan je ook vertellen hoeveel data een web spider per dag verwerkt. Dus, plaats je verse content op een regelmatige basis, dan heb je positieve resultaten in deze statistieken.
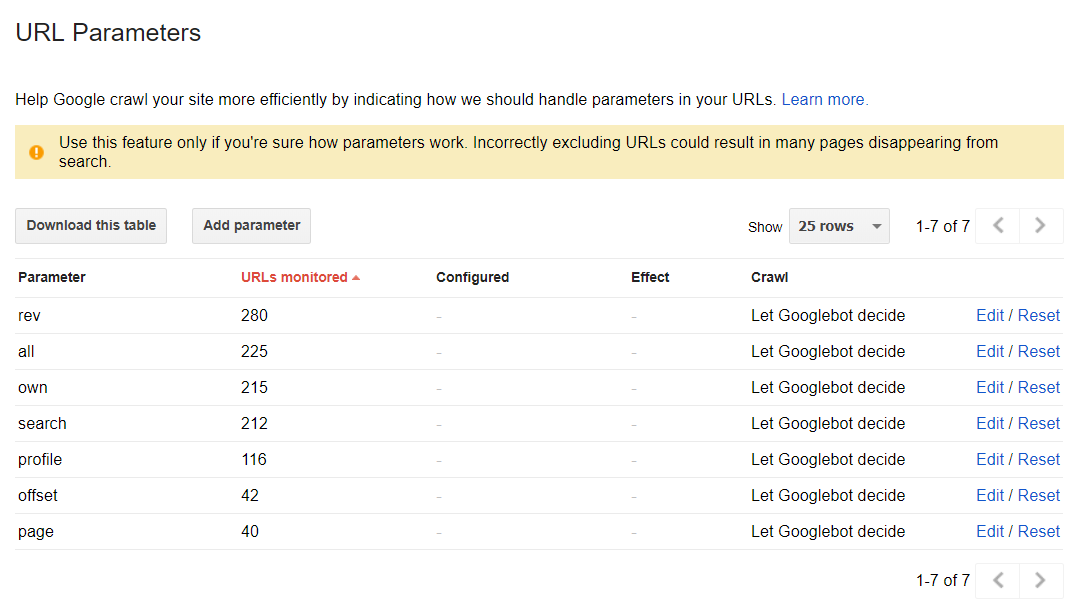
De parameters van de URL
Deze sectie helpt je om te ontdekken hoe Google crawlt en indexeert, door URL-parameters te gebruiken. Normaal gesproken worden alle pagina gecrawld aan de hand van de beslissingen van de web spiders: